Paper Details
Title: Flamingo: A Visual Language Model for Few-Shot Learning
Authors: Jean-Baptiste Alayrac*, Jeff Donahue*, Pauline Luc*, Antoine Miech*, Iain Barr†, Yana Hasson†, Karel Lenc†, Arthur Mensch†, Katie Millican†, Malcolm Reynolds†, Roman Ring†, Eliza Rutherford†, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan* (* indicates equal contributions)
Institution: DeepMind
Conference: 36th Conference on Neural Information Processing Systems (NeurIPS)
Year of Publication: 2022
Link: https://arxiv.org/abs/2204.14198
Key Focus:
Flamingo is a Visual Language Model (VLM) designed for few-shot learning, enabling rapid adaptation to multimodal tasks with minimal task-specific data. By integrating pre-trained vision and language models through innovations like GATED XATTN-DENSE layers and the Perceiver Resampler, Flamingo processes interleaved sequences of text, images, and videos to generate context-aware outputs. It achieves state-of-the-art performance on diverse benchmarks without fine-tuning, demonstrating strong generalization by leveraging large-scale web-sourced multimodal datasets. This model sets a new standard for efficient and versatile multimodal learning.
💡 Key point: 간단하게 Pretrained된 Vision 모델과 Language 모델을 연결하여 새로운 모델 구조 제시
📃 Summary
1. Introduction
최근 contrastive objective로 훈련된 Visual Language Model(VLM)은 추가적인 fine-tuning 없이도 새로운 task에 대한 zero-shot이 가능해졌다. 하지만, 이러한 모델들은 단순히 텍스트와 이미지 간의 유사도를 이용하기 때문에 classification과 같이 결과 집합이 한정된 경우에만 적용될 수 있다는 한계가 있었다. 또한, 언어 생성 능력이 부족하여 captioning, visual question-answering과 같은 Open-ended task에는 적합하지 않다는 문제점이 있었다.
해당 논문에서는 몇 가지 입출력 예제만으로도 다양한 open-ended vision and language task 에서 few-shot learning 의 SOTA를 달성한 VLM 모델, Flamingo를 제안한다.
Contributions of Flamingo
- 캡션 생성, 시각적 질문 응답 등 멀티모달 작업에서 최첨단 성능을 달성함.
- 웹 기반 대규모 멀티모달 데이터로 훈련되어 별도 작업별 튜닝 없이 적응 가능함.
- 기존 모델 대비 적은 데이터로 SOTA를 초과하는 few-shot 학습 능력을 입증함.

2. Approach
Flamingo는 텍스트와 이미지/비디오가 섞인 입력 데이터를 받아 자유 형식 텍스트를 출력하는 multimodal VLM 이다.
다음의 두 구성 요소는 모델의 핵심 구조이다.
- Perceiver Resampler
- 비전 인코더에서 추출된 시공간적 특징(from 이미지/비디오)을 받아 고정된 수의 시각적 토큰을 생성함.
- 이 시각적 토큰은 모델이 텍스트 생성 시 시각적 정보를 활용할 수 있도록 함.
- 새로운 교차 주의 계층
- 새로 초기화된 cross-attention 계층이 사전 학습된 언어 모델 레이어 사이에 삽입됨.
- 이를 통해 언어 모델이 시각적 맥락을 텍스트 예측 작업에 통합할 수 있음.
Flamingo는 는 텍스트 y가 삽입된 이미지/비디오 x를 조건으로 생성될 확률을 다음과 같이 모델링한다.
- p(y∣x): 텍스트 y의 전체 확률.
- yl: l-번째 텍스트 토큰.
- y<l: 이전의 모든 텍스트 토큰.
- x≤l: l-번째 텍스트 토큰 이전까지의 이미지/비디오.
Flamingo는 텍스트와 시각적 데이터를 삽입 처리(interleaved sequence)할 수 있는 능력을 활용하여 텍스트, 이미지, 비디오가 섞인 입력 처리가 가능하여 GPT-3와 유사한 few-shot 학습이 가능하며, 다양한 데이터셋에서 학습되어 캡션 생성, 질문 응답 등의 다양한 작업에서 효율적이라는 장점을 갖는다. 또한, Perceiver Resampler와 같은 모듈을 통해 시각적 특징과 언어 데이터를 자연스럽게 연결한다는 장점 역시 갖는다.
2.1. Visual processing and the Perceiver Resampler
Vision Encoder: from pixels to features.
- Vision Encoder: 이미지 데이터의 Feature를 추출하는 역할을 수행하는 모듈
- 입력 데이터: 이미지, 비디오에서 추출된 다양한 크기의 시각적 특징
- 출력 데이터: 고정된 수의 시각적 출력 토큰(본 논문에서는 64개), 계산 복잡성을 줄이며 효율적인 cross-attention 수행함.
Perceiver Resampler: from varying-size large feature maps to few visual tokens.
Vision Encoder와 frozen 언어 모델 간의 연결 역할을 하는 부분이다.
- VE로부터 전달받은 다양한 크기의 특징(from 이미지/비디오)을 고정된 수(본 논문에서는 64개)의 시각적 토큰으로 변환하여 vision-text cross-attention의 계산 복잡성을 줄임.
2.2. Conditioning frozen language models on visual representations
Flamingo는 Perceiver Resampler에서 생성된 시각적 표현을 활용하여 텍스트 생성을 수행하며, 이를 위해 사전 학습된 언어 모델(LM)에 새로운 GATED XATTN-DENSE 계층을 삽입하여 시각적 정보를 통합한다.
- Perceiver Resampler가 생성한 visual representation으로 조건화된 Transformer decoder로 텍스트 생성함.
- 사전 학습된 언어 모델 블록을 freeze하고, layer 사이의 GATED XATTN-DENSE block을 삽입하여 Perceiver Resampler로부터 나온 시각적 출력에 cross-attention 적용함.
2.3. Multi-visual input support: per-image/video attention masking
Flamingo는 다중 이미지/비디오 입력을 처리하며, single-image cross-attention 방식으로 효율성을 극대화한다.
- 학습 데이터에 포함되지 않은 시각적 시퀀스 길이에도 자연스럽게 일반화함.
- 학습 중 최대 5개의 시각적 입력만 사용하지만, 평가 시 최대 32개의 입력을 처리 가능함.
2.4. Training on a mixture of vision and language datasets
Flamingo 모델을 웹에서 수집한 세 가지 유형의 데이터셋(웹페이지에서 추출된 삽입된 이미지와 텍스트 데이터셋, 이미지-텍스트 쌍, 비디오-텍스트 쌍)을 사용하여 학습시켰다.
M3W: Interleaved image and text dataset.
- 약 4300만 개의 웹페이지 HTML에서 텍스트와 이미지를 추출함.
- 이미지 위치를 텍스트에 <image> 태그로 표시하고, <EOC> 토큰으로 구간을 마감함.
- 각 문서에서 최대 256개의 텍스트 토큰과 최대 5개의 이미지를 포함하며, 계산 비용을 줄이기 위해 초과 이미지는 제외함.
Pairs of image/video and text.
- ALIGN: ALT 텍스트가 포함된 18억 개의 이미지와 텍스트 쌍.
- LTIP: 긴 설명을 포함하는 3억 1200만 개의 이미지와 텍스트 쌍으로 구성된 자체 수집 데이터셋.
- VTP: 약 22초 길이의 2700만 개의 짧은 비디오와 설명으로 구성된 데이터셋.
Multi-objective training and optimisation strategy.
- Flamingo는 텍스트 토큰과 시각적 입력에 대한 조건부 확률을 계산하며, 데이터셋별 negative log-likelihoods를 가중합하여 최소화한다.
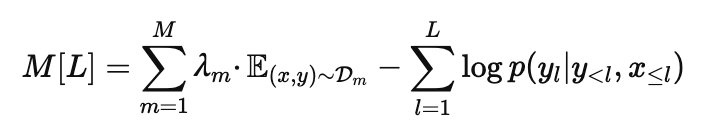
- λm: 각 데이터셋에 대한 가중치를 조정해 성능을 최적화.
- 모든 데이터셋에서 기울기를 누적시키는 방식이 효과적임.
2.5. Task adaptation with few-shot in-context learning
Flamingo는 학습이 완료된 후 in-context learning 방식을 사용하여 새로운 시각적 작업에 빠르게 적응할 수 있었으며, 이는 GPT-3의 텍스트 기반 프롬프트 학습과 유사하지만, 멀티모달 작업으로 확장되었다.
3. Experiments
3.1. Few-shot learning on vision-language tasks
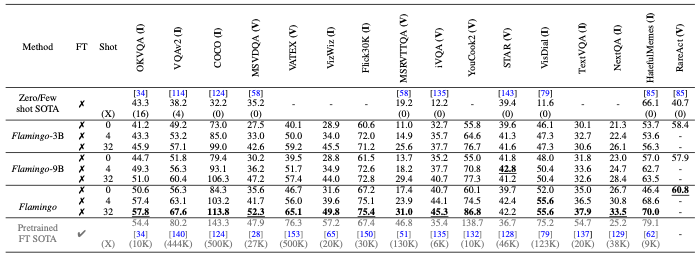
Few-shot results.
- Flamingo는 16개의 벤치마크에서 기존의 zero-shot 및 few-shot 방법을 큰 차이로 능가함.
- 작업당 단 4개의 예제만으로도 새로운 작업에 효율적으로 적응 가능함을 보임.
- Fine-Tuned SotA와의 비교:
- Flamingo는 수십만 개의 주석 데이터를 사용해 fine-tuning된 최신 기술(Fine-Tuned SotA)과 비교해 경쟁력을 갖춤.
- 특히 6개의 작업에서는 주석 데이터 없이 SotA를 능가함.
- 일반화 능력: DEV 벤치마크에서 설계된 모델임에도 다른 벤치마크에서도 높은 성능을 보여 설계의 범용성을 입증함.
Scaling with respect to parameters and shots.
- 모델 크기와 성능 관계:
- 모델 크기가 클수록 few-shot 성능이 향상되며, 이는 GPT-3와 유사한 경향성을 보임.
- Flamingo-80B와 같은 대형 모델은 더 많은 샷에서 성능을 더욱 잘 활용함.
- 입력 데이터 유연성:
- M3W 학습에서 5개의 이미지로 제한되었음에도, 추론 시 최대 32개의 이미지 또는 비디오를 활용 가능함을 보임.
- 이는 Flamingo의 유연한 구조가 다양한 입력 데이터를 효과적으로 처리할 수 있음을 시사함.
3.2. Fine-tuning Flamingo as a pretrained vision-language model

- Flamingo의 가장 큰 모델을 대상으로 fine-tuning을 적용한 결과, in-context 학습 대비 성능이 향상됨을 확인함.
- 특히 다음의 다섯 개 작업에서 새로운 SotA 달성: VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes
- Flamingo는 적은 데이터로도 높은 성능을 내는 few-shot 학습뿐 아니라, 더 많은 데이터를 활용한 fine-tuning에서도 강력한 성능을 발휘함을 확인함.
- 다양한 작업에서 SotA를 갱신하였으며, 이로서 범용 멀티모달 모델로서의 가능성을 증명함.
3.3. Ablation studies
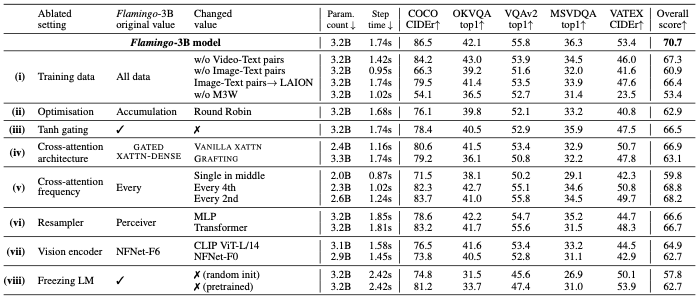
Importance of the training data mixture.
- M3W 데이터셋 제거: 성능이 17% 이상 감소하였으며, 이미지-텍스트 삽입 데이터의 중요성을 확인함.
- 기존 이미지-텍스트 쌍 제거: 성능이 9.8% 감소, 다양한 유형의 데이터셋 필요성 입증함.
- 비디오-텍스트 쌍 제거: 모든 비디오 작업에서 성능 저하를 보임.
- LAION-400M 대체: Flamingo의 이미지-텍스트 쌍을 LAION-400M으로 교체 시 성능 약간 감소함.
Visual conditioning of the frozen LM.
- 0으로 초기화된 tanh 게이팅 제거: 성능 4.2% 감소 및 학습 안정성 저하됨.
- Conditioning Architecture 비교: VANILLA XATTN과 GRAFTING 모두 Flamingo의 GATED XATTN-DENSE 방식보다 나쁨.
Compute/Memory vs. performance trade-offs.
- GATED XATTN-DENSE 계층 삽입 빈도:
- 모든 레이어에 삽입 시 성능은 향상되지만 파라미터 수와 시간 복잡성이 증가함.
- 4개 레이어마다 삽입 시 학습 속도 66% 증가하는 반면 성능은 1.9% 감소함 → 효율성 확보
- Perceiver Resampler 비교: MLP 및 기본 Transformer 대비 성능과 속도 모두 우수함.
Vision encoder.
- NFNet-F6 vs. CLIP ViT-L/14: NFNet-F6가 CLIP 대비 5.8%, NFNet-F0 대비 8.0% 우위를 보임.
- 이로서 강력한 비전 백본 사용의 중요성을 확인함.
Freezing LM components prevents catastrophic forgetting.
- Scratch에서 학습 시: 성능 12.9% 감소 → 사전 학습의 중요성 입증함.
- Fine-Tuning 시: 성능 8.0% 감소하고 Catastrophic Forgetting 현상 발생함.
- LM 고정: 사전 학습된 언어 모델을 유지하며 새로운 작업에 적응할 때 가장 효과적임.
4. Related work
Language modelling and few-shot adaptation.
- Flamingo는 Chinchilla 70B 언어 모델을 기반으로, in-context 학습 방식을 채택해 새로운 작업에 빠르게 적응함.
- 프롬프트에 예제를 제공하는 간단한 접근으로, 복잡한 metric learning이나 meta-learning을 피함.
When language meets vision.
- Flamingo는 fine-tuning 없이 이미지, 비디오, 텍스트가 섞인 시퀀스를 자유롭게 처리 가능함.
- 텍스트 생성 기능을 갖춘 첫 비전-언어 모델로, 기존 대조 학습 기반 모델과 차별화됨.
Web-scale vision and language training datasets.
- 수작업 주석 데이터 대신 비전-텍스트 쌍과 삽입된 웹페이지 데이터를 학습에 활용함.
- Few-shot 학습과 시각적 작업을 효과적으로 지원하며, 새로운 데이터 접근 방식을 제시함.
5. Discussion
Limitations
- 사전 학습된 언어 모델의 한계 계승:
- Flamingo는 사전 학습된 언어 모델(LMs)을 기반으로 구축되었기 때문에 언어 모델의 단점을 그대로 물려받음.
- 환각(hallucination)과 비논리적 추측(unfounded guesses)
- 학습된 시퀀스 길이를 초과하는 입력에 대한 일반화 부족
- 학습 중 낮은 샘플 효율성
- 이러한 문제를 해결하면 VLM 연구가 가속화되고 Flamingo의 성능이 향상될 가능성이 있다고 평가함.
- Flamingo는 사전 학습된 언어 모델(LMs)을 기반으로 구축되었기 때문에 언어 모델의 단점을 그대로 물려받음.
- 분류 성능 부족:
- Flamingo의 분류 성능은 텍스트-이미지 검색에 최적화된 대조 학습 모델보다 떨어짐.
- 다만 대조 학습 모델은 분류 작업에 최적화된 반면, Flamingo는 더 광범위한 작업(특히 개방형 작업)을 처리할 수 있도록 설계되었다는 점에서 차이가 있으며, 두 접근 방식을 결합한 통합 연구가 필요함.
- In-Context Learning의 제한:
- In-context learning
- 장점: 단순한 배포, 하이퍼파라미터 튜닝 없이 작동 가능
- 단점: 데모(demonstration)의 구성에 민감, 샷(shot) 수가 늘어날수록 성능 확장성과 추론 비용이 급격히 감소
- 이는 Few-shot 학습과의 결합으로 상호 보완적인 장점을 활용할 기회가 있을 것으로 생각함.
- In-context learning
Societal impacts
- 긍정적인 부분
- Flamingo는 데이터가 부족한 환경에서도 비전문가가 높은 성능을 낼 수 있도록 지원하여 접근성을 크게 향상.
- 다양한 작업에 빠르게 적응할 수 있어 연구 및 응용 분야에서 유용.
- 잠재적 위험
- 언어 모델과 동일한 문제점: 공격적인 언어 출력, 사회적 편향 및 고정관념 전파, 민감한 정보 유출 등
- 시각적 입력 처리의 위험성:
- 입력 이미지의 성별 및 인종 편향을 포함한 비전 시스템의 전형적인 문제
- Flamingo의 시각적 인식 기능이 잘못된 응용 프로그램으로 이어질 가능성
- 완화 전략: 인종 및 성별 편향과 독성 출력에 대한 조기 연구와 완화 전략을 통해 위험 감소 노력
Conclusion
Flamingo는 최소한의 작업별 학습 데이터로 이미지와 비디오 작업에 적용할 수 있는 범용 모델 패밀리를 제안하였다. 또한, 기존 비전 모델을 넘어 모델과의 대화(chatting)와 같은 인터랙티브한 가능성을 탐구하였다. 이는 사전 학습된 대형 언어 모델과 강력한 비전 모델의 연결이 범용 시각적 이해로 나아가는 중요한 단계임을 입증하였다.