Paper Details
Title: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Authors: Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
Conference: International Conference on Learning Representations (ICLR 2021)
Year of Publication: 2021
Link: https://arxiv.org/abs/2010.11929
Key Focus:
This paper introduces the Vision Transformer (ViT), which applies the transformer model, traditionally used in NLP tasks, directly to image patches for image recognition. It eliminates the reliance on convolutional networks and demonstrates that transformers, pre-trained on large-scale datasets and fine-tuned for smaller image recognition tasks, can outperform convolutional neural networks (CNNs) such as ResNet. By training on large datasets like ImageNet-21k and JFT-300M, ViT achieves state-of-the-art results on benchmarks such as ImageNet, CIFAR-100, and VTAB. The model handles image classification tasks with fewer computational resources, and its performance improves as the dataset size increases. ViT achieves an accuracy of 88.55% on ImageNet, 94.55% on CIFAR-100, and 77.63% on VTAB tasks.
💡 Key point: CNN 없이 트랜스포머만 적용한 Vision Transformer(ViT)
📄 Summary of Paper
1. Introduction
기존의 컴퓨터 비전 분야에서는 CNN이 널리 사용되었다. Transformer는 원래 자연어 처리(NLP) 분야에서 널리 사용되는 모델로, 특히 대규모 텍스트 데이터를 처리하는 데 강력한 성능을 보이는 모델이다. 해당 연구에서는 이 Transformer를 컴퓨터 비전 작업, 특히 이미지 분류에 직접 적용하는 방식을 제안한다.
핵심 아이디어는 다음과 같다.
입력 이미지를 작은 패치 단위로 나누고, 각각의 패치를 일종의 '단어 토큰'처럼 처리하여 Transformer에 입력한다. 이렇게 이미지 자체를 토큰화하고, 그것을 Transformer 구조에 입력하게 되면 CNN 없이도 이미지 작업 수행이 가능해진다. 이는 기존 CNN에서 발생하는 많은 복잡성을 줄이면서도 성능은 유지하거나 오히려 향상시킨다는 장점을 지닌다.
2. Related Work
자연어 처리(NLP) 분야
2017년 Transformer가 처음 제안된 이후, NLP 분야에서는 혁신적인 모델로서 널리 사용되었다.
트랜스포머 기반 모델들은 대규모 텍스트 말뭉치(corpus)에서 사전 학습한 후, 특정 작업에 맞춰 미세 조정하는 방식으로 학습된다. 대표적인 예로 BERT(Devlin et al., 2019)와 GPT(Radford et al., 2018, 2019)가 있으며, 이들은 각각 텍스트 복원 및 언어 모델링 작업을 통해 사전 학습된다.
컴퓨터 비전(CV) 분야
CV 분야에서는 CNN이 오랫동안 널리 사용되어왔으며, 최근에는 Transformer와의 결합을 시도한 다양한 연구가 있었다. 하지만 Transforemr를 이미지 작업에 적용할 때 픽셀 간 상호작용의 복잡성으로 인해 계산 비용이 매우 커지는 문제가 발생하기 때문에, 이를 해결하기 위해 국소적 자기 집중이나 희소 트랜스포머 등 다양한 최적화 기법이 제안되었다.
3. Method
3.1. Vision Transformer (ViT)

해당 논문에서 제안한 Vision Transformer(ViT)의 구조는 위와 같다.
기본적으로는 Transformer의 구조를 따르지만, 입력으로 이미지를 사용하는 방식에 차별점이 있다. 이미지 인식을 위해 ViT는 먼저 이미지를 고정 크기의 패치로 나눈 후, 각 패치를 선형적으로 임베딩하여 트랜스포머의 입력 시퀀스로 변환한다. 이러한 패치는 NLP에서 사용하는 단어 토큰과 유사한 방식으로 처리된다.
가장 앞에 들어간 Position Embedding은 이미지 패치들의 순서(위치값)를 보존하는 역할을 한다.

Position Embedding 은 위와 같은 구조로 되어있는데, 왼쪽 상단 패치는 왼쪽 상단 모서리가, 중앙 패치는 중심 부분이, 오른쪽 하단 패치는 오른쪽 하단 모서리가 가장 활성화되어 있는 것을 볼 수 있다. Position Embedding을 각각에 맞는 패치에 더하여 위치값을 보존한다.
먼저 ViT 의 작동 과정을 자세히 설명하면 다음과 같다.

1. 우선 원본 이미지를 패치 수대로 자르고 각각의 패치를 1차원으로 만든다.
2. 여러 개의 패치를 Linear Projection 을 통해 하나의 벡터로 만든다. (벡터 사이즈 = 벡터 차원 x 9)
3. 벡터를 3배의 dimension으로 늘리고 이것을 3등분해서 각각 Query, Key, Value로 할당한다.
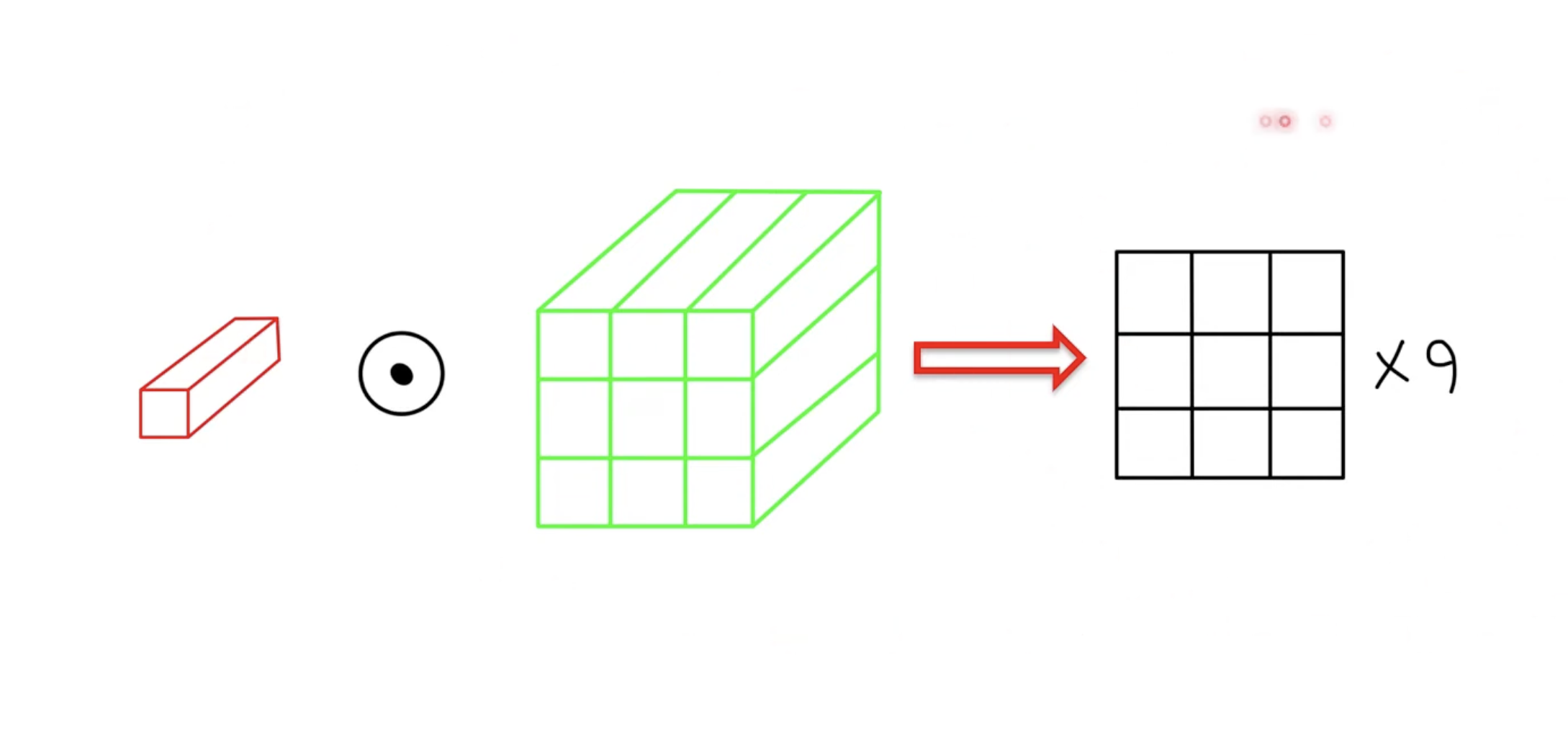
4. 각 Query가 전체 Key 벡터에 각각 dot product 연산을 수행하여 9개의 output 을 생성한다.
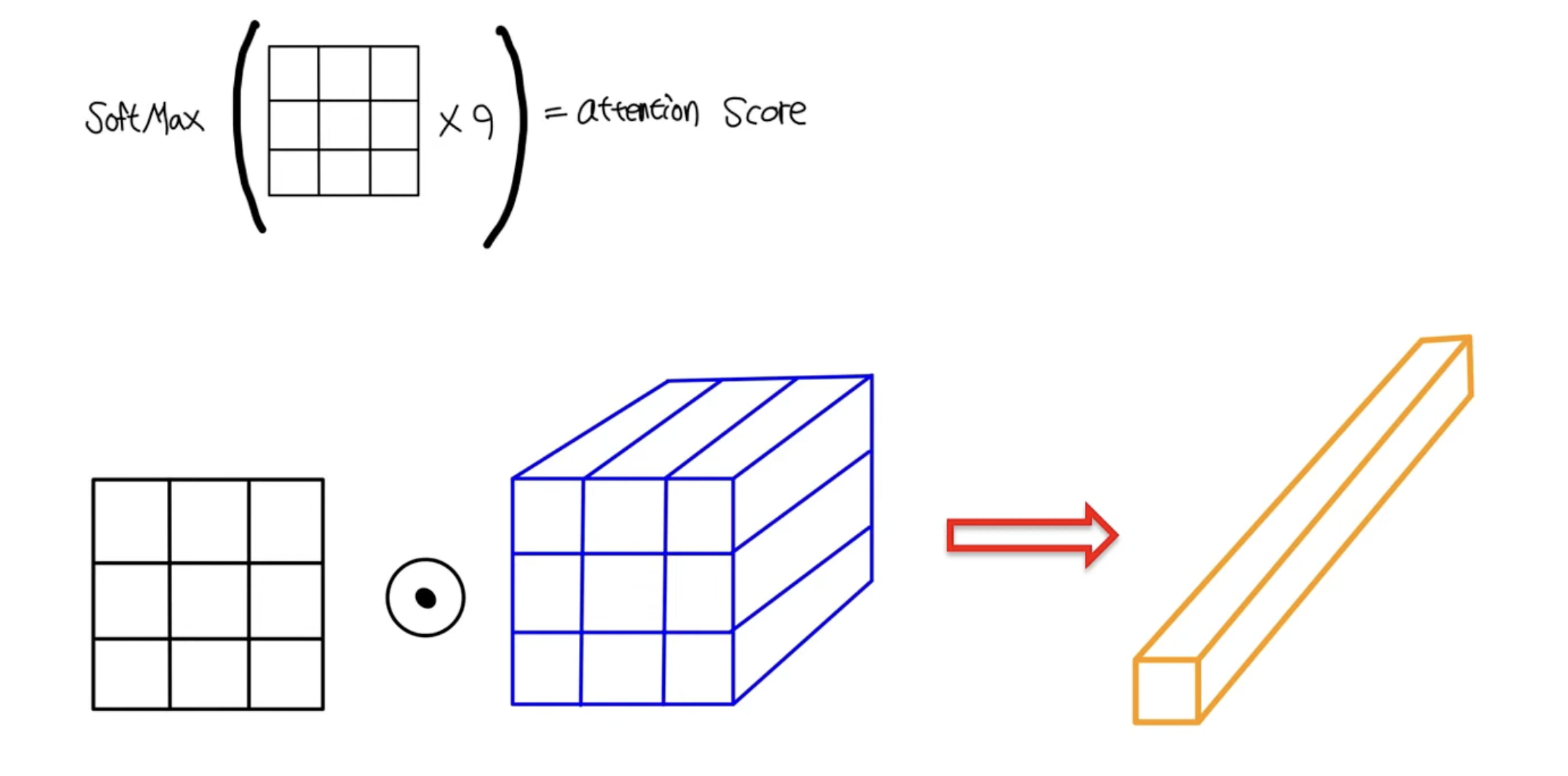
5. output에 Softmax를 취하여 attention score를 구한다.
6. attention score를 다시 한번 전체 Value와 dot product 연산을 취하여 최종적으로 attention module의 output vector를 출력한다.
위의 과정을 나타내는 수식은 다음과 같다.
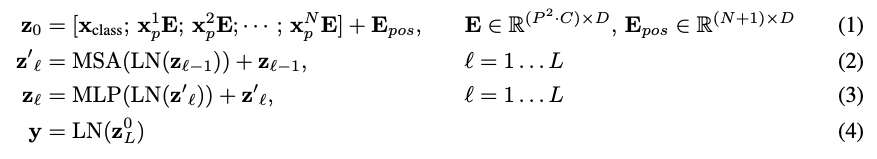
- (1)에서 $z_0$는 클래스 토큰과 패치 임베딩을 포함한 벡터를 의미한다. $x_p$는 각 패치, $E$는 패치 임베딩에 대한 Linear projection 행렬, $E_{pos}$는 Position Embedding 행렬이다.
- (2)는 각 층에서 레이어 정규화를 적용한 후 Multi-head Self Attention의 입력으로 넣어 값을 얻는다. 그리고 여기에 기존의 값(z_{l-1})을 residual connection 기법으로 더한다.
- (3)은 각 층에서 다시 한 번 레이어 정규화를 적용하고 MLP를 거친 출력에 한 번 더 residual connection 기법으로 기존 값을 더해준다.
- (4)에서는 마지막 층의 클래스 토큰 $z_0^L$에 레이어 정규화(Layer Normalization)를 적용하여 최종 출력 $y$ 벡터를 구하는 과정이다.
출력된 $y$ 벡터를 입력값으로 받은 MLP를 통해 Image Classification을 수행한다.
유도 편향 (Inductive Bias)
Vision Transformer(ViT)은 CNN보다 훨씬 적은 이미지 특화 유도 편향을 가진다. CNN에서는 지역성(locality), 2차원 이웃 구조(2D neighborhood structure), 변환 불변성(translation equivariance)이 모델 전체에서 적용되지만, ViT에서는 MLP 계층에서만 지역적이고 변환 불변적이고, Self-Attention 계층은 전역적이기 때문이다.
초반에 이미지를 패치로 나누는 과정과 나중에 해상도가 다른 이미지에 맞춰 Position Embedding을 조정하는 것 외에는 2D 구조 정보가 거의 사용되지 않는다. 또한, Position Embedding은 초기화 시 패치의 2D 위치에 대한 정보를 제공하지 않으며, 모든 공간적 관계는 학습을 통해 알아낸다.
이미지 특화 유도 편향(image-specific inductive bias)이란?
모델이 특정 유형의 이미지에 대해 더 잘 작동하도록 유도되거나 편향되는 현상.
컴퓨터 비전 또는 이미지 처리 모델에서 발생하는 편향 중 하나이며, 주로 모델이 훈련된 데이터셋에 특정 유형의 이미지가 불균형적으로 포함되어 있을 때 발생한다. 예를 들어, 모델이 훈련되는 동안 특정 객체, 장면, 또는 스타일의 이미지가 많이 포함되어 있으면, 그 모델은 그러한 이미지에 더 높은 성능을 보일 수 있지만, 반대로 그렇지 않은 유형의 이미지에 대해서는 성능이 저하될 수 있다.
하이브리드 아키텍처 (Hybrid Architecture)
각각의 패치를 Linear projection을 통해 벡터로 만드는 것이 아니라 CNN을 통해 얻은 피쳐 맵을 Transformer의 input vector로 사용해서 패치를 얻는 방법이다. 이러한 하이브리드 모델에서는 패치 임베딩 projection을 CNN 피처 맵에서 추출된 패치에 적용한다. 패치가 1x1 크기인 특수한 경우에는 입력 시퀀스는 피처 맵의 공간 차원을 평탄화하여 트랜스포머 차원에 투영한다.
3.2. Fine-tuning and Higher resolution
ViT는 대규모 데이터셋에서 사전 학습한 후, 더 작은 다운스트림 작업에 맞춰 fine-tuning이 진행된다. 이 과정에서, 사전 학습된 prediction head를 제거하고 새로운 $D \times K$ feedforward layer를 추가한다. 여기서 $K$는 다운스트림 작업의 클래스 수를 의미한다. fine-tuning시, 사전 학습보다 더 높은 해상도로 학습하는 것이 유리할 때가 많다. 다만, 더 큰 해상도의 이미지를 입력하는 경우, 패치 크기는 유지하므로, 입력 시퀀스의 길이는 길어지게 된다. Transformer는 메모리 제약 내에서 긴 시퀀스를 처리할 수 있지만, 사전 학습된 position embedding이 유효하지 않을 수 있다. 이를 해결하기 위해 2D interpolation을 사용해 position embedding을 조정한다.
4. Experiments
4.1. Setup
논문에서는 모델의 확장성을 탐구하기 위해 ILSVRC-2012 ImageNet 데이터셋(1k 클래스, 130만 개 이미지), 확장된 ImageNet-21k(21k 클래스, 1400만 개 이미지), JFT(18k 클래스, 3억 300만 개 고해상도 이미지)를 사용하였다. 사전 학습된 데이터셋을 다운스트림 작업의 테스트 세트와 중복되지 않도록 처리하고, ImageNet의 원래 검증 레이블과 정제된 Real Labels, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102 등의 벤치마크로 모델을 전이 학습한다.
모델은 BERT에서 사용된 트랜스포머 구조를 기반으로 하며, "Base", "Large", "Huge" 세 가지 모델 크기를 사용한다. VTAB 분류 작업에도 평가를 진행하며, 자연, 특화, 구조화된 이미지 작업으로 나뉘어 다양한 작업에 대해 성능을 평가한다.
4.2. Comparison to State of the Art
해당 논문에서 ViT 모델의 비교 대상은 다음의 두 모델이다.
- Big Transfer(BiT): 대규모 ResNet을 사용해 지도 전이 학습을 수행하는 모델
- Noisy Student: ImageNet과 JFT-300M 데이터셋에서 라벨이 제거된 상태에서 준지도 학습을 통해 학습된 대규모 EfficientNet 모델
비교 결과는 다음과 같다.
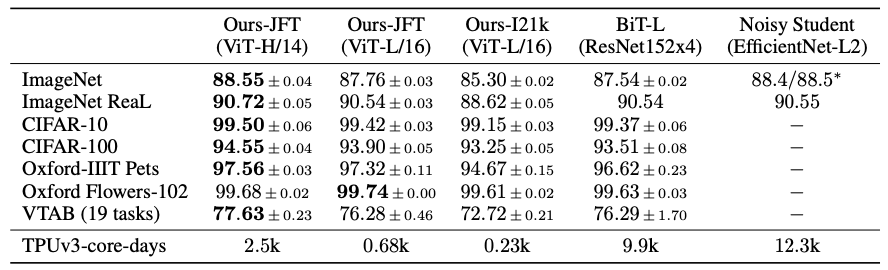
JFT-300M에서 사전 학습된 Vision Transformer 모델(ViT-H/14, ViT-L/16)은 BiT-L 모델을 뛰어넘는 성능을 보인다. 특히, ViT-H/14는 ImageNet, CIFAR-100, VTAB에서 우수한 성능을 보였으며, 더 적은 계산 자원으로 사전 학습되었음을 확인할 수 있다. 또한, TPUv3 core-days는 ViT 모델이 BiT-L이나 Noisy Student에 비해 훨씬 적은 자원을 사용했음을 보여준다.
VTAB 작업의 성능을 Natural, Specialized, and Structured task groups로 나누어 평가한 결과는 다음과 같다.
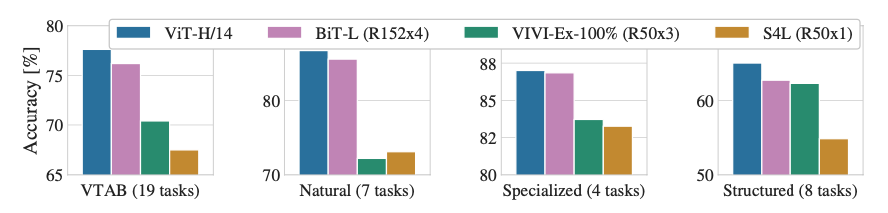
ViT-H/14는 모든 그룹에서 우수한 성능을 보여줬으며, 특히 자연과 특화 작업에서는 BiT-L을 능가하는 것을 볼 수 있다. 구조화된 작업에서는 ViT-H/14가 다른 모델과 비슷한 성능을 기록했지만 여전히 우수한 성과를 보이고 있다.
4.3. Pre-training Data Requirements
앞서 4.2에서 ViT는 대규모 데이터셋인 JFT-300M에서 사전 학습했을 때 좋은 성능을 보였다. 해당 모델은 ResNet에 비해 이미지에 대한 유도 편향이 적기 때문에 데이터셋 크기가 얼마나 중요한지를 다음의 두 실험을 통해 확인하였다.
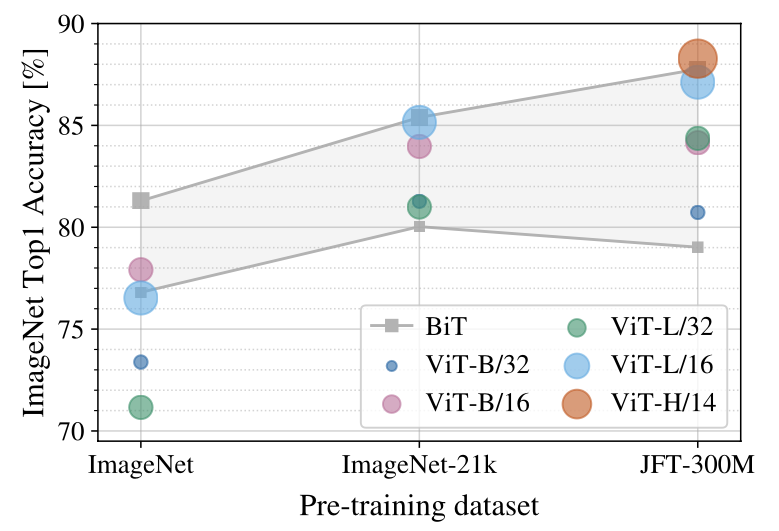
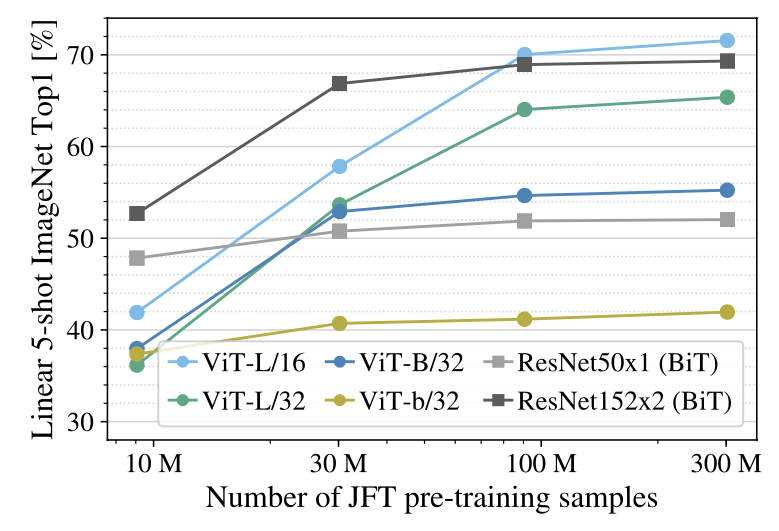
Figure 3은 ImageNet으로의 전이 학습 결과를 보여준다.
작은 데이터셋에서 사전 학습한 경우, 큰 ViT 모델은 BiT ResNet보다 성능이 낮지만, 큰 데이터셋(JFT-300M)에서 사전 학습한 경우에는 더 큰 ViT 변형이 더 작은 변형을 능가하며, 결국 ResNet을 능가하는 성능을 보인다.
Figure 4는 ImageNet에서 사전 학습 데이터 크기에 따른 Linear few-shot 평가 결과를 나타낸다.
ResNet 모델은 작은 데이터셋에서 우수하지만, 더 큰 데이터셋에서는 성능 향상이 한계에 도달하는 것을 볼 수 있다. 반면에 ViT 모델은 데이터셋의 크기가 커질수록 성능이 오히려 향상되는 경향을 보이며, 특히 100M 이상의 데이터셋에서 ResNet을 능가하는 것을 볼 수 있다. 이는 ViT가 대규모 데이터셋에서 더 효과적임을 보여주며, 동시에 few-shot 학습에서도 높은 잠재력을 가진다는 것을 시사한다.
4.4. Scaling Study
JFT-300M에서의 전이 성능을 평가하여 다양한 모델의 확장성 연구를 수행한 결과는 다음과 같다.
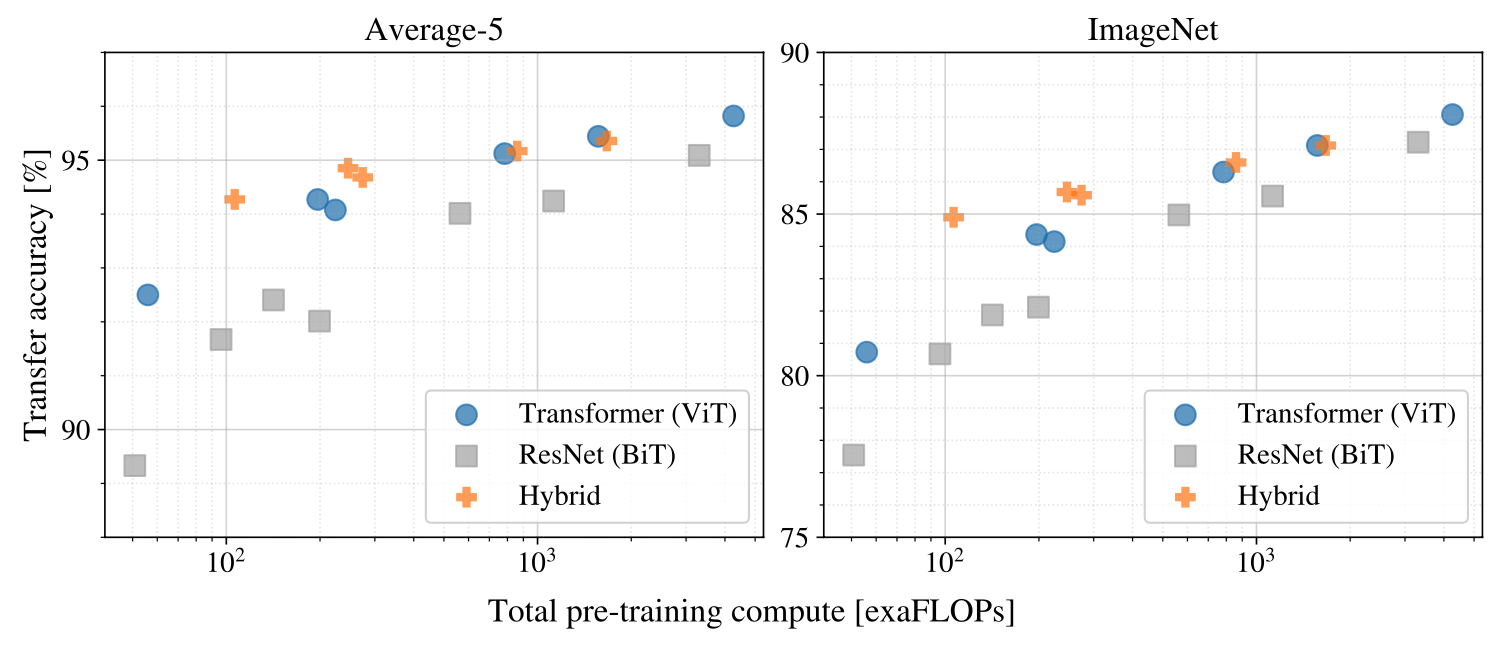
Figure 5는 다양한 아키텍처의 사전 학습 연산 비용 대비 성능을 비교한 결과이다.
ViT 모델은 ResNet 및 하이브리드 모델에 비해 훨씬 적은 계산량으로도 높은 성능을 달성하는 경향을 보인다. 특히 ViT 모델은 2~4배 적은 계산량으로도 같은 성능을 발휘하는 것을 확인할 수 있다. 하이브리드 모델은 작은 모델 크기에서는 ViT보다 약간 더 좋은 성능을 보이지만, 큰 모델 크기로 갈수록 그 차이가 줄어들면서 ViT가 더 유리해지는 경향을 보 인다.
4.5. Inspecting Vision Transformer
Vision Transformer가 이미지 데이터를 처리하는 방식을 이해하기 위해 내부 표현(internal representations)을 분석한 결과는 다음과 같다.
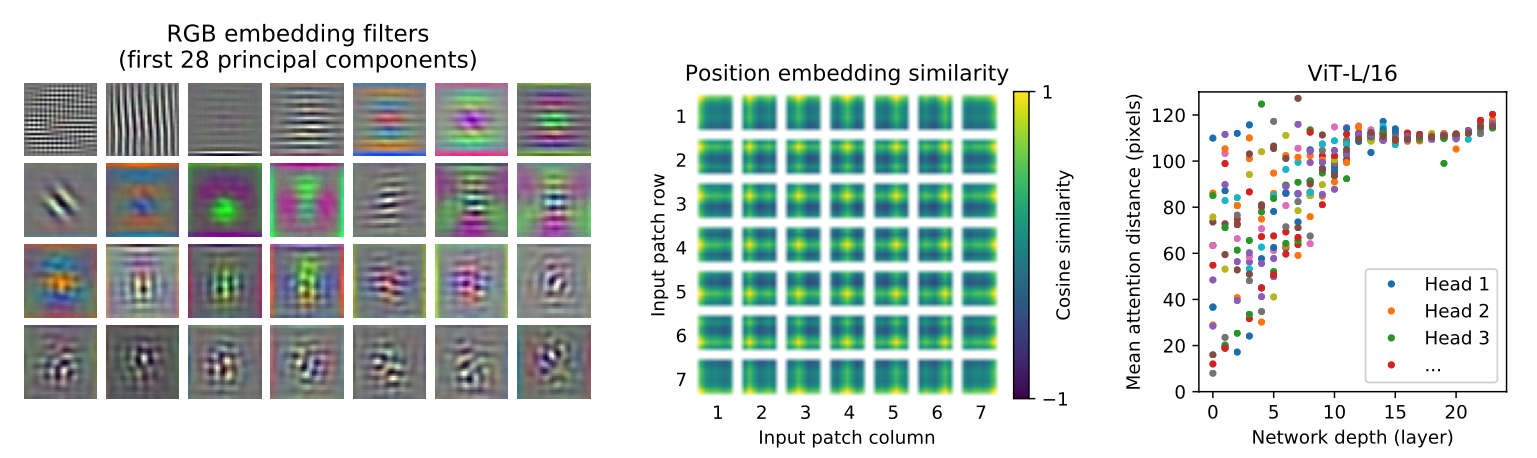

ViT는 첫 번째 층에서 이미지를 평탄화된 패치로 변환한 후 저차원 공간으로 투영한다. 이 과정에서 학습된 임베딩 필터는 패치 내부의 세부 구조를 표현하는 기저 함수 역할을 한다. 투영 후에는 위치 임베딩이 패치에 추가되어 이미지 내 패치 간 거리와 유사성을 학습한다. 이를 통해 가까운 패치는 유사한 임베딩을 가지며, 패치 간의 행렬 구조가 형성된다.
ViT의 자기 집중 메커니즘은 이미지 전체에서 정보를 통합하는 데 중요한 역할을 한다. 해당 연구에서는 네트워크가 어느 정도까지 이 기능을 활용하는지 평가했으며, 일부 헤드가 낮은 층에서도 이미지의 대부분에 주목하여 정보 통합을 수행한다는 것을 발견했다. 이는 모델이 이미지의 중요한 영역에 효과적으로 집중할 수 있음을 보여준다. 특히, ViT는 분류에 중요한 이미지 영역을 선택적으로 주목하여 높은 성능을 발휘할 수 있다.
4.6. Self-Supervision
Transformer의 성공은 대규모 자가 지도 사전 학습에도 크게 의존한다.
해당 연구에서는 BERT에서 사용된 마스킹된 언어 모델링을 모방하여 마스킹된 패치 예측을 적용한 자가 지도 학습을 실험했는데, 그 결과, 작은 ViT-B/16 모델이 ImageNet에서 79.9%의 정확도를 기록하며, 처음부터 학습했을 때보다 2%의 성능 향상을 보였으나, 지도 사전 학습에 비해서는 4% 뒤처졌다. 따라서 대조적 사전 학습(contrastive pre-training)에 대한 추가 연구 를 향후 연구 과제로 제시하고 있다.
5. Conclusion
기존 연구와 달리, Vision Transformer는 초기 패치 추출을 제외하고는 이미지 특화 유도 편향을 도입되지 않았다. 대신 이미지를 패치로 나누어 NLP에서 사용되는 표준 트랜스포머 인코더로 처리하는 단순하고 확장 가능한 방식을 채택했으며, 이 방식은 대규모 데이터셋에서 사전 학습했을 때 매우 효과적임을 연구를 통해 확인했다. ViT는 여러 이미지 분류 작업에서 최신 기술과 대등하거나 이를 능가하는 성능을 보였고, 사전 학습 비용 또한 비교적 저렴했다.
다만 해당 연구의 끝에서는 해결해야 할 과제들을 언급하고 있다.
- 다른 컴퓨터 비전 작업에 적용하는 것
- self-supervised pre-training을 계속 탐구하는 것
(초기 실험에서 자가 지도 학습을 통해 성능이 개선되긴 했으나, 대규모 지도 학습과의 성능 차이가 여전히 크기 때문) - ViT의 추가적인 확장을 통한 성능 향상
'논문 리뷰 > Computer Vision' 카테고리의 다른 글
| [논문 리뷰] V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation (0) | 2024.11.25 |
|---|---|
| [논문 리뷰] U-Net: Convolution Networks for Biomedical Image Segmentation (0) | 2024.11.18 |

