Paper Details
Title: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Authors: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Conference: NAACL 2019
Year of Publication: 2019
Link: https://arxiv.org/abs/1810.04805
Key Focus:
This paper introduces BERT (Bidirectional Encoder Representations from Transformers), a novel language representation model that pre-trains deep bidirectional representations by conditioning on both left and right contexts of a token in all layers. Unlike traditional models, which are typically unidirectional, BERT uses two primary pre-training tasks—Masked Language Modeling (MLM) and Next Sentence Prediction (NSP)—to achieve a rich understanding of context. The result is a pre-trained model that can be fine-tuned with minimal architectural adjustments to achieve state-of-the-art performance on a range of NLP tasks, including question answering and language inference.
💡Key point: 양방향 Transformer로 문맥의 양쪽 정보를 학습하여 다양한 NLP 작업에서 뛰어난 성능을 보이는 언어 모델 제안
📄 Summary of the Paper
1. Introduction
기존의 언어 모델 사전 학습은 NLP 작업의 성능을 크게 향상시켰다. 기존의 접근법에는 두 가지가 있다.
- Feature-based(ELMo): 사전 학습된 표현을 작업별 아키텍처에 추가로 사용함.
- Fine-tunin(OpenAI GPT): 좌측에서 우측으로의 아키텍처를 사용하며, 최소한의 작업별 파라미터로 모든 사전 학습된 파라미터를 조정함.
하지만, 기존 모델들은 주로 단방향(left-to-right) 구조로 작동하며, 양방향 문맥 학습에 한계가 있다. BERT(Bidirectional Encoder Representations from Transformers)는 이러한 한계를 극복하기 위해 개발된 모델로, 양방향 트랜스포머를 사용해 문맥을 양방향으로 학습하며, 마스킹 언어 모델과 다음 문장 예측을 결합해 보다 정교한 사전 학습을 수행한다.
- 마스킹 언어 모델(MLM, Masked Language Model): 입력 문장에서 일부 토큰을 마스킹하고, 문맥 기반으로 예측함.
- 다음 문장 예측(NSP, Next Sentence Prediction): 문장 간 관계를 학습해 문장 쌍의 표현을 사전 학습함
2. Related Work
단어의 널리 사용 가능한 표현을 학습하는 연구는 오랜 역사를 가지고 있으며, 비신경망 방법과 신경망 방법이 모두 포함된다.
2.1. Unsupervised Feature-based Approaches
사전 학습된 단어 임베딩은 처음부터 학습된 임베딩보다 성능이 우수하다. 이를 위해 좌측에서 우측으로의 언어 모델링과 좌우 문맥에서 올바른 단어를 구별하는 목표가 사용된다. 문장 및 단락 임베딩 연구는 후보 문장 순위 매기기, 이전 문장 기반의 다음 문장 생성, 디노이징 오토인코더 목표 등을 통해 발전해왔다. ELMo는 좌우 문맥에서 문맥 민감한 특징을 추출해 다양한 NLP 벤치마크에서 성능을 크게 향상시킨다.
2.2. Unsupervised Fine-tuning Approaches
초기 연구에서는 라벨이 없는 텍스트에서 단어 임베딩 파라미터만 사전 학습했다. 최근에는 문장이나 문서 인코더를 통해 문맥적 토큰 표현을 사전 학습하고 이를 감독된 다운스트림 작업에 미세 조정하는 방법이 널리 사용된다. 이러한 접근은 적은 수의 파라미터만 처음부터 학습하면 되기 때문에 효율적이다. OpenAI GPT는 이러한 방식으로 GLUE 벤치마크의 여러 문장 단위 작업에서 이전보다 뛰어난 성능을 기록했다. 좌측에서 우측으로의 언어 모델링과 오토인코더 목표가 이러한 모델을 사전 학습하는 데 사용된다.
2.3. Transfer Learning from Supervised Data
대규모 데이터셋을 활용한 감독된 작업에서 전이 학습이 효과적이라는 연구도 다수 있다. 자연어 추론과 기계 번역에서 대규모 사전 학습된 모델은 성능 향상에 기여한다. 특히, 컴퓨터 비전 연구에서는 ImageNet을 통해 사전 학습된 모델을 미세 조정하는 것이 성능 향상의 주요 방법으로 자리 잡고 있다.
3. BERT
BERT의 프레임워크는 사전 학습과 미세 조정이라는 두 단계로 구성된다.
사전 학습 중에는 다양한 사전 학습 과제를 통해 라벨이 없는 데이터로 모델을 학습시킨다. 미세 조정 단계에서는 BERT 모델을 사전 학습된 파라미터로 초기화하고, 다운스트림 작업의 라벨이 있는 데이터로 모든 파라미터를 미세 조정한다. 각 다운스트림 작업은 동일한 사전 학습된 파라미터로 초기화되지만, 별도의 미세 조정된 모델을 가짐. 이 섹션의 예제는 질의응답을 기반으로 설명된다.
BERT의 특이한 점은 다양한 작업에 걸쳐 통일된 아키텍처를 사용한다는 점이다. 이는 사전 학습 아키텍처와 최종 다운스트림 아키텍처 간의 차이가 거의 없음을 의미한다.
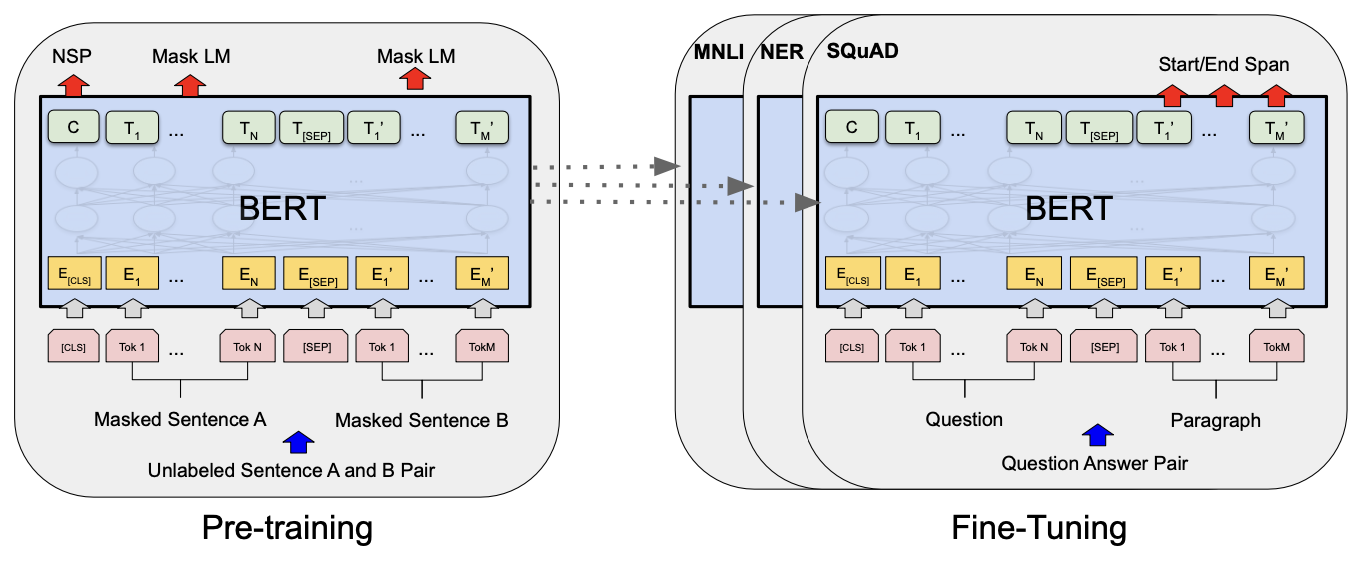

3.1. Pre-training BERT
BERT는 기존의 왼쪽에서 오른쪽 또는 오른쪽에서 왼쪽 언어 모델을 사용하지 않고, 두 가지 비지도 학습 과제를 통해 사전 학습한다.
Task #1: Masked LM
MLM은 일부 입력 토큰을 무작위로 마스킹하고, 해당 마스킹된 토큰을 예측함으로써 양방향 표현을 학습한다. 이 과정에서 각 마스킹된 토큰의 최종 히든 벡터는 어휘에 대한 소프트맥스 출력으로 입력되며, 모든 실험에서 시퀀스의 WordPiece 토큰 중 15%를 무작위로 마스킹한다.
Task #2: Next Sentence Prediction (NSP)
질의응답 및 자연어 추론과 같은 작업은 문장 간 관계 이해에 기반한다. 이를 위해 NSP 과제를 도입하여 문장 A 다음에 실제로 문장 B가 오는지를 예측한다. 50%는 실제 다음 문장, 나머지 50%는 임의의 문장으로 구성되다.
Pre-training data
BooksCorpus(8억 단어)와 영어 위키백과(25억 단어)를 사용하였다.
3.2. Fine-tuning BERT
BERT는 트랜스포머의 자기 주의 메커니즘 덕분에 다양한 다운스트림 작업을 모델링할 수 있다. 각 작업에 대해 작업별 입력과 출력을 BERT에 연결하고, 모든 파라미터를 끝까지 미세 조정한다. 텍스트 쌍을 포함하는 응용에서는 두 텍스트 쌍을 독립적으로 인코딩한 후, 양방향 교차 주의를 적용함. BERT는 자가 주의 메커니즘을 사용하여 두 단계를 하나로 통합한다.
미세 조정은 사전 학습보다 상대적으로 저렴하다. 모든 결과는 단일 클라우드 TPU에서 최대 1시간, 또는 GPU에서 몇 시간 내에 재현 가능하다.
4. Experiments
4.1. GLUE
GLUE(General Language Understanding Evaluation)는 다양한 자연어 이해 작업의 모음이다.
GLUE 작업에서 미세 조정을 위해, 입력 시퀀스를 3. BERT 에서 설명한 대로 나타내고, 첫 번째 입력 토큰([CLS])에 해당하는 최종 히든 벡터 $C \in R^H$를 집계 표현으로 사용하였다. 미세 조정 중에 도입되는 유일한 새로운 파라미터는 분류 레이어의 가중치 $W \in R^{K \times H}$이다. $C$와 $W$를 사용하여 표준 분류 손실($log(softmax(CW^T))$)을 계산한다.
실험 결과는 다음과 같다.

- $\text{BERT}_\text{BASE}$와 $\text{BERT}_\text{LARGE}$는 모든 작업에서 이전 시스템을 크게 능가하며, 각각 4.5%와 7.0%의 평균 정확도 향상을 달성함.
- $\text{BERT}_\text{BASE}$와 OpenAI GPT는 모델 아키텍처 측면에서 주의 마스킹을 제외하면 거의 동일함.
- 가장 널리 알려진 GLUE 작업인 MNLI에서 BERT는 4.6%의 절대적 정확도 향상을 달성함.
- 공식 GLUE 리더보드에서 $\text{BERT}_\text{LARGE}$는 80.5점을 기록했으며, 이는 OpenAI GPT의 72.8점보다 높은 점수임.
- $\text{BERT}_\text{LARGE}$는 특히 작은 데이터셋을 포함한 모든 작업에서 $\text{BERT}_\text{BASE}$보다 훨씬 뛰어난 성능을 보임.
4.2. SQuAD v1.1
SQuAD v1.1는 스탠포드 질의응답 데이터셋으로 10만 개의 크라우드소싱된 질문/답변 쌍으로 구성되어 있다. 주어진 질문과 답을 포함한 위키백과 본문을 기반으로 답변 텍스트 범위를 예측하는 작업이다.
질의응답 작업에서 입력 질문과 본문을 하나의 시퀀스로 나타내며, 질문은 $A$ 임베딩, 본문은 $B$ 임베딩을 사용한다. 미세 조정 중에 시작 벡터 $S \in R^H$와 종료 벡터 $E \in R^H$를 도입한다. 답변 범위의 시작이 될 확률은 $T_i$와 $S$ 를 내적한 후 softmax를 통해 계산된다. 끝 범위의 확률은 유사한 방식으로 계산되며, $i$부터 $j$까지의 후보 범위 점수는 $S \cdot T_i + E \cdot T_j 로 정의된다. $j \geq i$인 범위 중 최대 점수를 갖는 범위를 예측으로 사용한다. 학습 목표는 올바른 시작 및 끝 위치의 log-likelihood(로그 우도)의 합이다.
실험 결과는 다음과 같다.

BERT는 앙상블에서 +1.5 F1, 단일 시스템에서 +1.3 F1로 리더보드 상위 시스템보다 성능이 높음을 확인할 수 있다.
4.3. SQuAD v2.0
SQuAD 2.0은 주어진 문단에 짧은 답이 존재하지 않을 가능성을 추가하여 SQuAD 1.1의 문제 정의를 확장한 데이터셋이다. 답이 없는 질문을 [CLS] 토큰의 시작 및 종료 범위를 가진 답변으로 처리한다.
실험 결과는 다음과 같다.

BERT는 이전 최고 시스템(Top Leaderboard Systems)보다 F1 점수가 +5.1 개선된 것을 확인할 수 있다.
4.4. SWAG
SWAG(Situations With Adversarial Generations) 데이터셋은 113,000개의 문장 쌍 완성 예제로 구성되어 있으며, 일상적 상식 추론 능력을 평가하는 데이터셋이다. 주어진 문장을 기반으로 가장 그럴듯한 이어지는 문장을 4개의 선택지 중에서 고르는 작업이다. 미세 조정 시, 각 선택지를 포함하는 4개의 입력 시퀀스를 생성하고, [CLS] 토큰 표현과의 내적을 통해 각 선택지의 점수를 계산하여 소프트맥스 계층으로 정규화한다.
실험 결과는 다음과 같다.

$\text{BERT}_\text{LARGE}$가 기존의 ESIM+ELMo 시스템보다 +27.1%, OpenAI GPT보다 8.3% 높은 성능을 보였음을 확인할 수 있다.
5. Ablation Studies
5.1. Effect of Pre-training Tasks
BERT의 깊이 있는 양방향성을 강조하기 위해, $\text{BERT}_\text{BASE}$와 동일한 사전 학습 데이터, 미세 조정 방법, 하이퍼파라미터를 사용하여 두 가지 사전 학습 목표를 평가하였다.
- No NSP: 다음 문장 예측(NSP) 작업 없이 마스킹 언어 모델(MLM)만 사용하여 훈련된 양방향 모델.
- LTR & No NSP: 표준 좌측-우측(LTR) LM을 사용하여 훈련된 좌측 컨텍스트 전용 모델로, NSP 작업 없이 훈련됨.

Table 5에 따르면 NSP 제거 시 QNLI, MNLI, SQuAD 1.1에서 성능이 상당히 저하되는 것을 확인할 수 있다. 또한, No NSP와 LTR & No NSP를 비교하여 양방향 표현 학습의 중요성을 평가한 결과, LTR 모델은 모든 작업에서 MLM 모델보다 성능이 낮았으며, 특히 MRPC와 SQuAD에서 큰 차이를 보였다.
5.2. Effect of Model Size
모델 크기의 효과를 분석하기 위해 다른 레이어 수, 히든 유닛 수, 어텐션 헤드 수를 가진 여러 BERT 모델을 훈련하여 실험한 결과는 다음과 같다.

Table 6의 결과에 따르면, 레이어 수, 히든 유닛 수, 어텐션 헤드 수를 늘릴수록 모델 정확도가 개선되는 것을 확인할 수 있다. 이는 BERT가 대규모 사전 훈련을 통해 소규모 데이터에서도 성능 향상이 가능하다는 것을 시사한다.
5.3. Feature-based Approach with BERT
기존 BERT 결과는 미세 조정 접근법을 사용하였으며, 단순한 분류 레이어를 사전 훈련된 모델에 추가하여 모든 파라미터를 하류 작업에 맞춰 조정했다. 하지만 사전 훈련된 모델에서 고정된 특징을 추출하는 Feature 기반 접근 방식도 있으며, 이를 실험한 결과는 다음과 같다.

Table 7에 따르면, Feature 기반 접근 방식에서 최상의 성능을 나타낸 방법이 미세 조정된 전체 모델보다 단지 0.3 F1만큼만 낮음을 보인다. 이는 BERT가 두 접근 방식 모두에서 효과적임을 의미한다.
6. Conclusion
최근 전이 학습을 통한 언어 모델의 발전은 비지도 사전 학습의 중요성을 입증하였으며, 자원이 적은 작업에서도 성능 개선을 가능하게 하였다. 해당 연구는 이를 더 나아가 깊은 양방향 아키텍처로 일반화하여, 동일한 사전 학습된 모델이 다양한 NLP 작업을 처리할 수 있도록 기여하였다는 점에서 의미를 갖는다.
'Research Reviews > Natural Language Processing' 카테고리의 다른 글
| [논문 리뷰] Attention is All You Need (1) | 2025.01.24 |
|---|---|
| [논문 리뷰] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (3) | 2024.12.16 |

