Paper Details
Title: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Authors: Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
Conference: Facebook AI Research, University College London, New York University
Year of Publication: 2021
Link: https://arxiv.org/abs/2005.11401
Key Focus:
This paper proposes the Retrieval-Augmented Generation (RAG) model to enhance performance in knowledge-intensive NLP tasks. RAG combines a pre-trained sequence-to-sequence model (BART) with Dense Passage Retrieval (DPR) to retrieve documents from non-parametric memory and generate factual, specific text based on them. The model achieves superior performance in tasks like open-domain QA, Jeopardy question generation, and fact verification compared to previous approaches. Additionally, RAG allows for knowledge updates by replacing its non-parametric memory without retraining. This structure enhances model interpretability, flexibility, and suitability for incorporating up-to-date information.
💡Key point:
📄 Summary of the Paper
1. Introduction
기존 사전 학습 모델들은 데이터로부터 심층적인 지식 학습을 통해 암묵적 지식 베이스로의 활용이 가능하지만, 다음과 같은 문제점을 갖는다.
- 메모리 확장 및 수정의 어려움
- 예측 근거 제공 부족
- 환각(hallucination) 문제
이를 해결하기 위한 접근법으로 해당 연구에서는 RAG을 제안한다.
여기서 RAG이란 사전 학습된 매개적 메모리 생성 모델에 비매개적 메모리를 추가하는 범용 미세 조정 방식을 의미한다.
retrieval-augmented generation (RAG) = pre-trained, parametric-memory generation models with a non-parametric memory through a general-purpose fine-tuning approach.
사전 학습된 seq2seq 모델(BART)과 밀도 벡터 기반 비매개적 메모리(Wikipedia 인덱스)를 결합한다.
Dense Passage Retriever(DPR)를 사용하여 입력에 따라 관련 문서를 검색한 뒤, BART가 이를 기반으로 출력을 생성한다.
RAG는 토큰 단위 또는 출력 단위로 잠재 문서를 주변화(marginalization)하여 최적의 정보를 활용하며, 생성기와 검색기를 함께 학습한다.

본 연구에서는 RAG이 Natural Questions, WebQuestions, CuratedTrec와 같은 오픈 도메인 QA 작업에서 기존의 추출 기반 모델과 전문화된 사전 학습 접근법을 능가하며 최첨단 성능을 달성했음을 보였다. 또한 MS-MARCO와 Jeopardy 질문 생성 작업에서는 BART보다 더 사실적이고 구체적이며 다양한 텍스트를 생성함을 확인했다. FEVER 사실 검증 작업에서도 강력한 성과를 보였으며, 비매개적 메모리를 교체하여 모델 지식을 동적으로 업데이트할 수 있음을 입증했다.
이 연구는 지식 집약적 NLP 과제에서 매개적 및 비매개적 메모리를 결합하여 모델의 성능과 유연성을 극대화할 수 있는 가능성을 제시한다.
2. Methods
RAG 모델은 입력 시퀀스 $x$를 사용해 텍스트 문서 $z$를 검색하고, 이를 맥락으로 활용하여 대상 시퀀스 $y$를 생성한다.
- 구성 요소:
- 검색기 $p_\eta(z|x)$: 쿼리 $x$에 따라 텍스트 문서 분포를 반환하며, 상위 K개의 문서로 한정된 분포를 생성.
- 생성기 $p_\theta(y_i|x, z, y_{1:i-1})$: 이전 토큰 $y_{1:i-1}$, 입력 $x$, 검색된 문서 $z$를 바탕으로 현재 토큰 $y_i$를 생성. 검색기와 생성기를 함께 학습하기 위해, 검색된 문서를 잠재 변수로 간주하여 이를 marginalization한다.
2.1. Models
RAG-Sequence Model
동일한 문서를 사용해 전체 시퀀스를 생성.
- 검색기에서 상위 K개의 문서를 검색하고, 생성기가 각 문서에 대해 출력 시퀀스 확률을 생성한 뒤, 이를 주변화해 최종 확률 $p(y|x)$를 계산.

RAG-Toekn Model
각 토큰에 대해 서로 다른 문서를 선택해 출력 생성 가능.
- 검색기에서 상위 K개의 문서를 검색한 뒤, 생성기는 각 토큰 $y_i$를 생성할 때마다 다른 문서를 사용 가능.
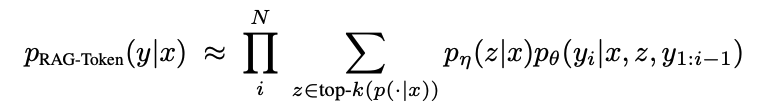
RAG-Sequence는 동일한 문서를 기반으로 전체 시퀀스를 예측하지만, RAG-Token은 더 다양한 문서에서 정보를 통합해 답변을 생성할 수 있다는 특징이 있다.
2.2. Retriever: DPR
검색 구성 요소 $p_\eta(z|x)$는 Dense Passage Retriever(DPR)로 구현된다.

- DPR은 바이인코더(bi-encoder) 구조를 사용하며, 문서와 쿼리를 각각 밀도 벡터(dense vector)로 변환하여 내적(inner product)을 기반으로 상위 K개의 문서를 검색.
- 문서 표현 $d(z)$와 쿼리 표현 $q(x)$는 BERT 기반 인코더로 생성되며, 최대 내적 검색(Maximum Inner Product Search, MIPS)을 통해 효율적으로 검색.
- TriviaQA와 Natural Questions 데이터셋으로 사전 학습된 DPR을 사용하며, 문서 인덱스는 비매개적 메모리로 간주.
2.3. Generator: BART
생성기 구성 요소 $p_\theta(y_i|x, z, y_{1:i-1})$는 BART-large를 사용하여 구현된다.
- BART는 사전 학습된 seq2seq 변환기로, 입력 $x$와 검색된 문서 $z$를 단순히 concatenate하여 출력 생성.
- 디노이징 목적과 다양한 노이징 함수를 활용해 학습되었으며, 다양한 생성 작업에서 최첨단 성능을 기록.
- BART의 매개변수 $\theta$는 매개적 메모리로 간주.
2.4. Training
검색기와 생성기는 입력/출력 쌍 $(x_j, y_j)$에 대한 음의 주변 로그 가능도 $)-\log p(y_j|x_j)$를 최소화하는 방식으로 공동 학습된다.
- 문서 인코더(BERTd_d)를 학습 중 업데이트하는 것은 비용이 크기 때문에, 고정된 상태로 유지하며 쿼리 인코더(BERTq_q)와 생성기(BART)만 미세 조정.
- REALM과 달리 문서 인덱스를 주기적으로 업데이트하지 않아도 높은 성능을 달성.
2.5. Decoding
RAG-Token 디코딩
각 토큰 $y_i$에 대해 상위 K개의 문서에서 주변화된 확률 $p'_\theta(y_i|x, y_{1:i-1})$을 계산하고, 이를 표준 빔 디코더에 적용한다.
RAG-Sequence 디코딩:
각 문서 $z$에 대해 빔 검색을 수행하여 각 가설 $y$의 확률을 계산한 뒤, 문서 간 확률을 합산해 최종 확률을 계산한다.
긴 출력 시퀀스의 경우, 추가 계산 비용을 줄이기 위해 빠른 디코딩(Fast Decoding)을 활용해 후보군에 없는 가설에 대해 추가 패스를 생략한다.
3. Experiments
Experiment Setting
RAG는 다양한 지식 집약적 과제에서 실험되었으며, 비매개적 지식 소스로 Wikipedia December 2018 dump를 사용한다.
- Wikipedia의 각 기사를 100단어 청크로 나눠 총 2100만 개의 문서를 구성.
- 문서 임베딩은 문서 인코더를 사용해 계산되며, FAISS 기반 MIPS(Massive Inner Product Search) 인덱스를 구축해 빠르게 검색.
- 학습 시 각 쿼리에서 상위 $k$개의 문서를 검색하며, $k \in \{5, 10\}$로 설정. 테스트 시 $k$는 개발 데이터를 기반으로 최적화.
3.1. Open-domain Question Answering
오픈 도메인 QA는 지식 집약적 과제에서 널리 사용되는 실세계 응용(real-world application)이다.
- 질문과 답변을 입력-출력 텍스트 쌍 $(x, y)$으로 간주하며, 정답의 음의 로그 가능도를 최소화해 RAG를 학습.
- 다음 두 가지 QA 접근법과 비교:
- 추출 기반 QA(extractive QA): 검색된 문서에서 정답을 추출하며, 비매개적 지식을 활용.
- 폐쇄형 QA(Closed-Book QA): RAG처럼 답변을 생성하지만 검색 없이 매개적 지식만 활용.
<데이터셋>
- Natural Questions (NQ), TriviaQA (TQA), WebQuestions (WQ), CuratedTrec (CT).
- CT와 WQ는 데이터셋이 작아 NQ RAG 모델로 초기화.
- TQA Wiki 테스트 세트를 사용해 T5 모델과 비교.
<평가>
- EM(Exact Match, 정답 일치) 점수를 기준으로 성능 평가.
3.2. Abstractive Question Answering
RAG는 단순히 정답을 추출하는 것을 넘어 자유로운 형태의 추상적 텍스트 생성이 가능하다.
- MSMARCO NLG 과제 v2.1에서 RAG의 자연어 생성(NLG) 성능 평가.
- 제공된 문단을 사용하지 않고 질문과 답변만을 활용해 MSMARCO를 오픈 도메인 추상적 QA 과제로 처리.
- 일부 질문은 gold passages 없이 답변하기 어려워 성능이 낮아질 수 있지만, RAG는 매개적 지식을 활용해 합리적인 답변을 생성.
3.3. Jeopardy Question Generatoin
RAG의 생성 능력을 QA 외의 과제에서 평가하기 위해 Jeoparday Question Generation을 수행한다.
Jeopardy Question은 entity와 관련된 사실을 기반으로 정답을 추측하는 독특한 형식으로, 정확성과 사실성이 요구된다.
<실험 세부사항>
- SearchQA 데이터를 사용하며, 학습 100K, 개발 14K, 테스트 27K.
- BART와 비교하며, Q-BLEU-1 메트릭으로 평가.
<평가 기준>
- 사실성(Factuality): 문장이 신뢰할 수 있는 외부 출처로 입증 가능한가.
- 구체성(Specificity): 입력과 출력 간 상호 의존성이 높은가.
- 인간 평가자는 BART와 RAG가 생성한 질문을 비교하여 선호도를 평가.
3.4. Fact Verification
FEVER는 자연어 주장(claim)을 기반으로 Wikipedia를 검색하여 다음 중 하나로 분류:
- 주장이 지원됨(Supports).
- 주장이 반박됨(Refutes).
- 충분한 정보가 없어 검증 불가(Not enough info).
<평가 방식>
- FEVER 클래스 레이블을 단일 출력 토큰으로 매핑해 학습.
- 검색된 증거에 대한 감독 신호 없이 학습하며, 이는 실제 응용에서 감독 신호가 없는 경우에도 활용 가능.
- 두 가지 분류 작업을 실험:
- 3-way 분류: Supports, Refutes, Not enough info.
- 2-way 분류: Supports, Refutes.
- 레이블 정확도(Accuracy)를 기준으로 평가.
4. Results
4.1. Open-domain Question Answering

Table 1에 나타난 바와 같이 RAG는 네 가지 오픈 도메인 QA 작업(NQ, TQA, WQ, CT)에서 새로운 최고 성능을 기록한다.
특히 TQA에서는 T5 모델과 비교할 수 있는 분할에서 최고의 성능을 보이는 것을 알 수 있다.
- RAG의 특징: "폐쇄형" 모델(매개적 지식만 활용)의 생성 유연성과 "개방형" 모델(검색 기반)의 성능을 결합.
- REALM과 T5+SSM: Salient Span Masking과 같은 고비용의 사전 학습 없이도 RAG는 강력한 결과를 달성.
- RAG와 DPR 비교: RAG의 검색기는 DPR로 초기화되었으며, DPR은 Natural Questions와 TriviaQA를 기반으로 검색 감독 신호를 활용. 그러나 RAG는 별도의 랭커(re-ranker)나 추출 기반 리더(extractive reader) 없이도 최첨단 성능을 달성.
생성 기반 접근의 이점을 따져보자면, 문서에 정답이 명시적으로 포함되어 있지 않아도 힌트를 바탕으로 정답을 생성할 수 있었다.
NQ 데이터셋에서 RAG는 검색된 문서에 정답이 존재하지 않아도 11.8% 정확도를 기록했으며, 이는 추출 기반 모델의 0%보다 월등히 높은 수치르 기록한다.
4.2. Abstractive Question Answering

Table 2에 따르면, RAG-Sequence는 Open MS-MARCO NLG 작업에서 BART를 BLEU 점수에서 2.6 포인트, Rouge-L 점수에서 2.6 포인트 능가한다.
- 최첨단 모델은 골드 문단을 활용하지만, RAG는 이를 사용하지 않음.
- 일부 질문은 골드 문단이 없으면 답변이 불가능함.
- Wikipedia만으로는 모든 질문에 답할 수 없음에도 불구하고 성능이 높음.

또한, Table 3 의 결과에 따르면 RAG 모델은 BART와 비교해 더 구체적이고 사실적인 답변을 생성하였다.
4.3. Jeopardy Question Generatoin
Table 2에 따르면, RAG-Token이 RAG-Sequence보다 제퍼디 질문 생성에서 더 나은 성능을 보이며, 두 모델 모두 BART를 능가하는 것을 알 수 있다.
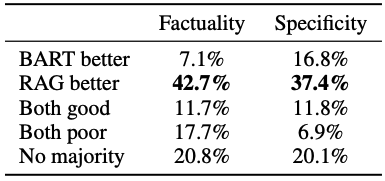
또한, 인간 평가 결과(Table 4)는 다음과 같았다.
- 사실성(Factuality): RAG가 BART보다 더 사실적인 결과를 생성한 경우가 42.7%로, BART의 7.1%를 크게 앞섬.
- 구체성(Specificity): RAG가 BART를 능가하는 경우가 37.4%로 평가됨.
Jeopardy Question 또한 앞서 언급한 바와 같이(Table 3) The Divine Comedy와 같은 예제에서 RAG 모델은 더 구체적인 정보까지 포함함을 알 수 있다.

Figure 2 에 따르면 jeopardy question 생성 시, 특정 문서의 후처 확률(posterior)이 높은 경우는 다음과 같았다.
- "The Sun Also Rises"는 문서 2에 집중.
- "A Farewell to Arms"는 문서 1에 집중.
이는 첫 토큰이 생성된 후, 문서 후처 확률은 평평해짐을 의미하며, 모델의 매개적 지식(parametric memory)이 제목 완성을 담당한다는 것을 의미한다.
4.4. Fact Verification
Table 2에서 RAG는 FEVER 데이터셋의 3-way 분류 작업에서 최첨단 모델 대비 4.3% 이내의 성능을 기록한다.
RAG는 검색된 증거에 대한 감독없이 학습되었음에도, 복잡한 파이프라인 모델과 비슷한 성능을 달성하였다.
2-way 분류에서는 RoBERTa 모델과 비교해 정확도 차이가 2.7%에 불과한다.
또한, RAG의 증거 검색 분석 결과, 상위 k개의 문서 중 가장 높은 확률로 검색된 문서가 FEVER의 골드 증거 문서와 일치하는 비율은 상위 1위 문서는 71%, 상위 10위 문서는 90%로 나타났다.
4.5. Additional Results
1) 생성 다양성

- RAG-Sequence는 RAG-Token보다 더 다양한 출력을 생성하며, 두 모델 모두 BART보다 다양성이 높다.
- MSMARCO와 제퍼디 질문 생성 작업에서 RAG는 더 높은 distinct n-gram 비율을 기록한다.
2) 검색 기능 비교

- 고정 검색기(frozen retriever)를 사용하는 경우 성능이 저하되었으며, 학습된 검색기가 모든 작업에서 더 나은 성능을 보였다.
- BM25와 비교하면,
- FEVER: BM25가 더 나은 성능을 기록(75.1% → 91.6%)했으나, 이는 엔터티 중심 검색에 BM25가 적합하기 때문.
- Open-Domain QA: 차별화된 검색(differentiable retrieval)이 더 큰 개선을 가져왔다.
3) 인덱스 교체
RAG의 비매개적 메모리는 쉽게 업데이트할 수 있습니다.
- 2016년과 2018년 Wikipedia 덤프를 사용하여 세계 지도자 목록을 기반으로 질문:
- 2016년 인덱스: 2016년 지도자에 대해 70% 정확도.
- 2018년 인덱스: 2018년 지도자에 대해 68% 정확도.
- 불일치된 인덱스: 정확도가 급감(12% → 4%).
이는 단순히 인덱스를 교체하는 것만으로도 RAG의 세계 지식을 쉽게 업데이트할 수 있음을 의미한다.
4) 검색 문서 수 효과

- Open-Domain QA:
- RAG-Sequence는 더 많은 문서를 검색할수록 성능이 개선되며, RAG-Token은 k=10k=10에서 성능이 최고점에 도달.
- MS-MARCO:
- RAG-Token은 더 많은 문서를 검색하면 Rouge-L 점수가 상승하지만, Bleu-1 점수는 하락.
- RAG-Sequence는 검색된 문서 수의 영향을 덜 받는다.
5. Related Work
Single-Task Retrieval
이전 연구는 특정 NLP 작업(오픈 도메인 QA, 사실 검증, 장문 QA, 번역 등)에서 검색이 성능을 크게 향상시킴을 보여주었다.. 그러나 대부분은 개별 작업에 맞춘 접근이었다. 반면, RAG는 단일 검색 기반 아키텍처를 다양한 작업에 적용하여 강력한 성능을 입증했다.
General-Purpose Architectures for NLP
사전 학습된 언어 모델은 검색 없이도 다양한 NLP 작업에서 성공을 거두었으며, 대표적으로 GPT-2, BART, T5가 있다. 이 모델들은 판별 및 생성 작업에서 뛰어난 성능을 기록했다. RAG의 목표는 사전 학습된 생성 모델에 검색 모듈을 추가하여 범용 아키텍처의 적용 범위를 확장하고, 다양한 작업에서 성능을 강화하는 것이다.
Learned Retrieval
기존 연구는 검색 모듈을 특정 하위 작업(예: QA)을 위해 최적화하거나 잠재 변수 접근법을 활용했다. 그러나 대부분은 단일 작업에 집중하는 모습을 보였다. 반면에 RAG는 단일 검색 기반 아키텍처가 다양한 작업에 대해 미세 조정되어 강력한 성능을 달성할 수 있음을 보여준다는 점에서 차별성을 갖는다.
Memory-based Architectures
RAG의 문서 인덱스는 대규모 외부 메모리와 유사하며, 메모리 네트워크와 같은 구조와 연결된다.
이는 다음과 같은 장점으로 연결된다.
- 인간이 읽을 수 있음: 원시 텍스트를 사용해 해석 가능성을 제공.
- 수정 가능: 문서 인덱스를 편집해 모델의 메모리를 동적으로 업데이트할 수 있음.
이 접근법은 지식 기반 대화 모델에서도 활용되었지만, 기존 TF-IDF 방식 대신 RAG는 학습된 검색을 사용합니다
Retrieve-and-Edit approaches
RAG는 검색-편집 방식과 유사하지만, 다음과 같은 차별점을 가진다.
- 단순히 검색된 항목을 가볍게 편집하는 대신, 여러 문서의 내용을 통합함.
- 잠재 검색(latent retrieval)을 학습하고 증거 문서를 검색함.
이러한 점에서 RAG 기술은 검색-편집 작업에도 효과적으로 적용될 가능성이 있어 추가 연구의 가치가 있다고 평가한다.
6. Discussion
본 연구는 매개적 및 비매개적 메모리를 결합한 RAG 모델을 제안했으며, 오픈 도메인 QA에서 최첨단 성능을 달성함을 보였다. RAG는 BART와 비교해 사실적이고 구체적인 생성 결과를 제공하며, 인간 평가에서도 더 높은 선호도를 얻었다. 검색 구성 요소의 효과를 검증했으며, 검색 인덱스를 교체하여 모델을 재학습 없이 업데이트할 수 있음을 시연했다.
향후 연구에서는 두 구성 요소를 공동 사전 학습하는 방법을 탐구하고, 매개적 및 비매개적 메모리의 결합 방식을 개선하는 새로운 연구 방향을 열어갈 수 있다. RAG는 다양한 NLP 작업에 적용될 수 있는 확장 가능성을 보여주었다.
'논문 리뷰 > Natural Language Processing' 카테고리의 다른 글
| [논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (1) | 2024.11.11 |
|---|
